

ARM架构double计算比float计算快现象
在评估rk3588处理器性能发现,现在处理器计算双精度浮点比单精度浮点要快上不少,其测试程序如下
int main(){
auto a = HAL::time().ns();
float f1 = 0.1;
for (int i = 0; i < 1e7; i++)
{
if (i%2)
f1+=1e-2;
else
f1-=1e-2;
}
auto b = HAL::time().ns();
double d1 = 0.1;
for (int i = 0; i < 1e7; i++)
{
if (i%2)
d1+=1e-4;
else
d1-=1e-4;
}
auto c = HAL::time().ns();
std::cout<< b-a <<std::endl;
std::cout<< c-b <<std::endl;
std::cout<< f1 <<std::endl;
std::cout<< d1 <<std::endl;
return 0;
}rk3588测试结果
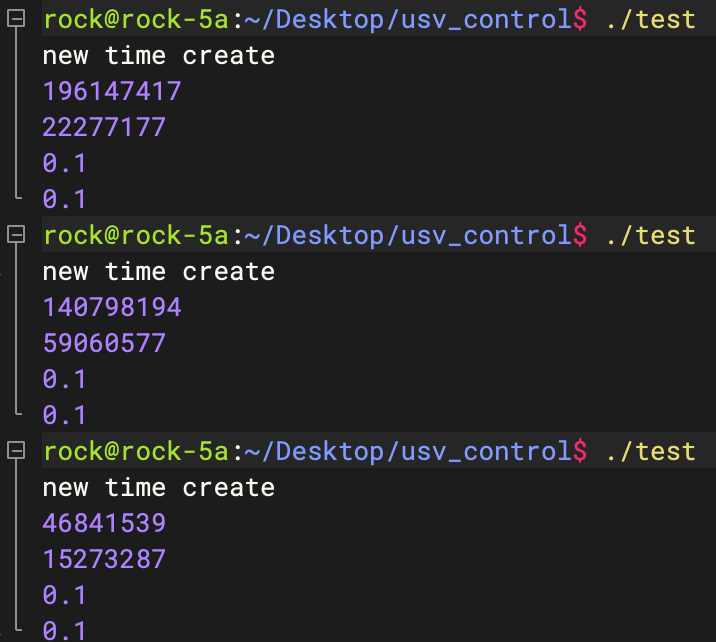
Apple M3测试结果
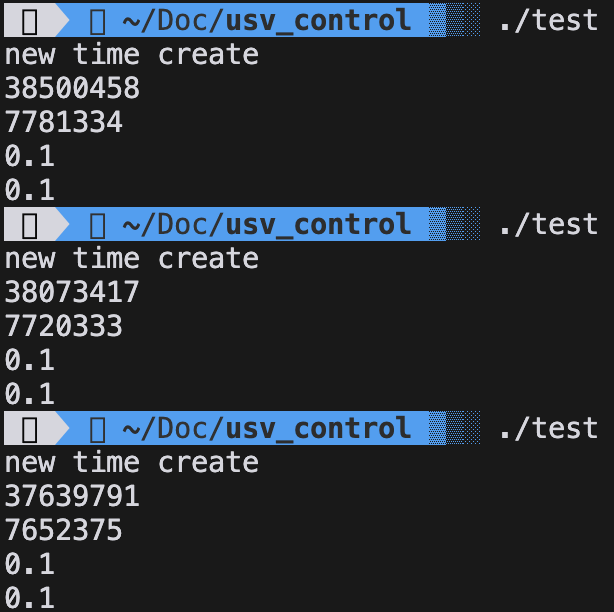
GPT的解释
现代 CPU 通常对 double 有很好的硬件支持,甚至可能对 double 进行 SIMD 优化。
• float 可能在一些架构中需要额外的内部转换(例如扩展为 double 计算后再存储为 float),导致额外的性能开销。
